How Atoms Fixed Flux

Photo by Mark Basarab on Unsplash
(Originally posted on HackerNoon).
Recoil introduced the atomic model to the React world. Its new powers came at the cost of a steep learning curve and sparse learning resources.
Jotai and Zedux later simplified various aspects of this new model, offering many new features and pushing the limits of this amazing new paradigm.
Other articles will focus on the differences between these tools. This article will focus on one big feature that all 3 have in common:
They fixed Flux.
Flux
If you don't know Flux, here's a quick gist:
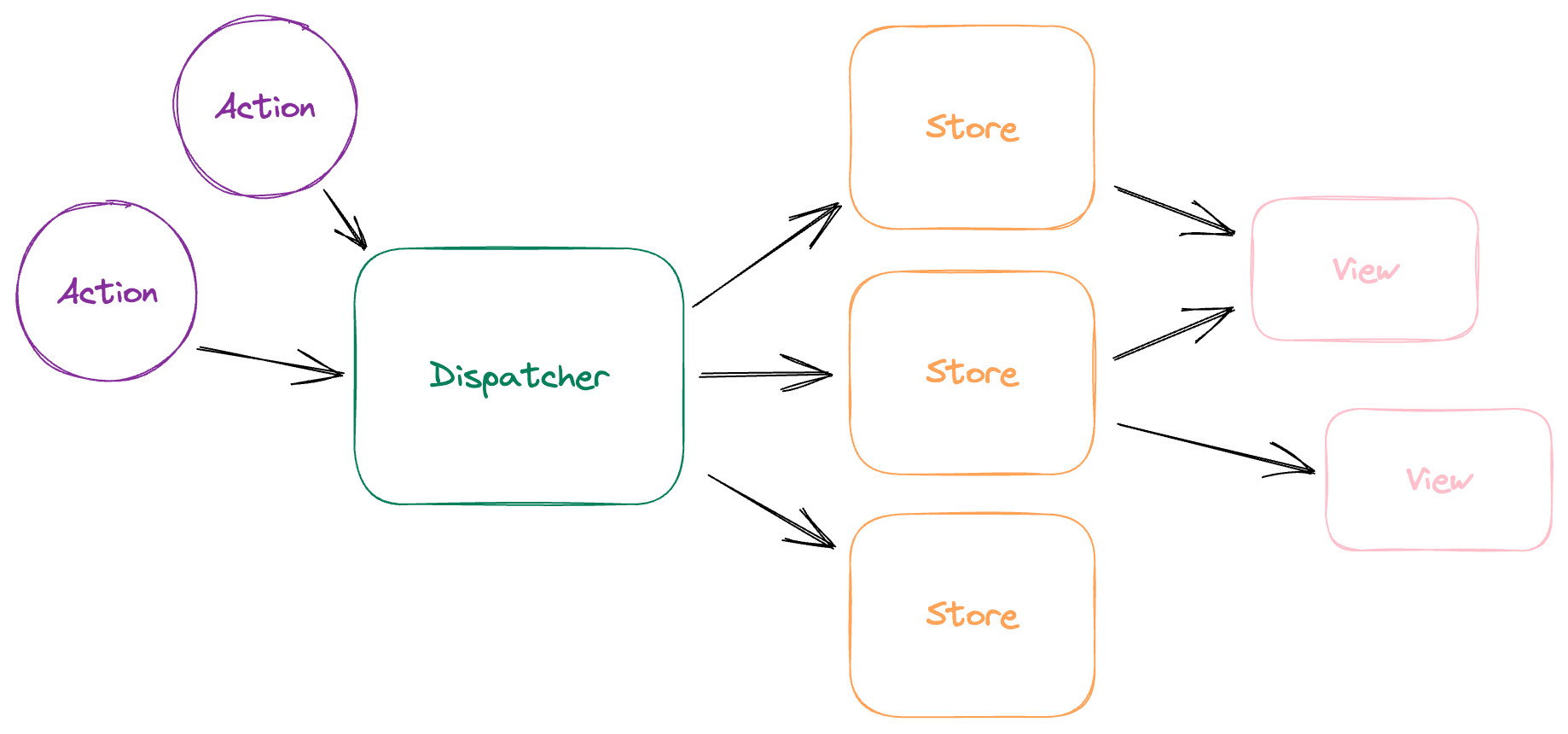
Besides Redux, all Flux-based libraries basically followed this pattern: An app has multiple stores. There is only one Dispatcher whose job is to feed actions to all the stores in a proper order. This "proper order" means dynamically sorting out dependencies between the stores.
For example, take an e-commerce app setup:
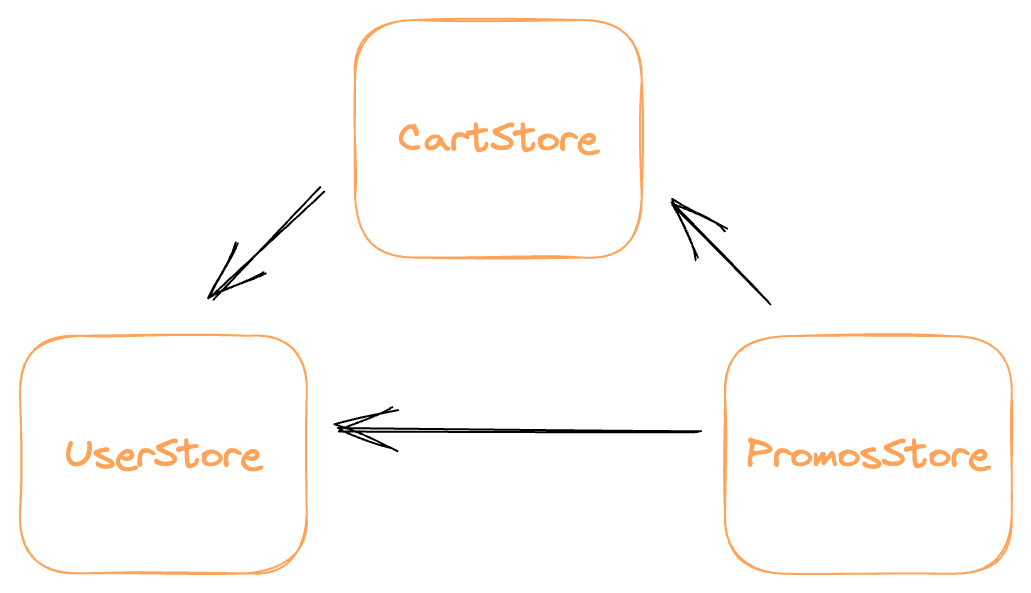
When the user moves, say, a banana to their cart, the PromosStore needs to wait for CartStore's state to update before sending off a request to see if there's an available banana coupon.
Or perhaps bananas can't ship to the user's area. The CartStore needs to check the UserStore before updating. Or perhaps coupons can only be used once a week. The PromosStore needs to check the UserStore before sending the coupon request.
Flux doesn't like these dependencies. From the legacy React docs:
The objects within a Flux application are highly decoupled, and adhere very strongly to the Law of Demeter, the principle that each object within a system should know as little as possible about the other objects in the system.
The theory behind this is solid. 100%. Soo ... why did this multi-store flavor of Flux die?
Dependency Trees
Well turns out, dependencies between isolated state containers are inevitable. In fact, to keep code modular and DRY, you should be using other stores frequently.
In Flux, these dependencies are created on the fly:
// This example uses Facebook's own `flux` library
PromosStore.dispatchToken = dispatcher.register(payload => {
if (payload.actionType === 'add-to-cart') {
// wait for CartStore to update first:
dispatcher.waitFor([CartStore.dispatchToken])
// now send the request
sendPromosRequest(UserStore.userId, CartStore.items).then(promos => {
dispatcher.dispatch({ actionType: 'promos-fetched', promos })
})
}
if (payload.actionType === 'promos-fetched') {
PromosStore.setPromos(payload.promos)
}
})
CartStore.dispatchToken = dispatcher.register(payload => {
if (payload.actionType === 'add-to-cart') {
// wait for UserStore to update first:
dispatcher.waitFor([UserStore.dispatchToken])
if (UserStore.canBuy(payload.item)) {
CartStore.addItem(payload.item)
}
}
})
This example shows how dependencies aren't directly declared between stores - rather, they're pieced together on a per-action basis. These informal dependencies require digging through implementation code to find.
This is a very simple example! But you can already see how helter-skelter Flux feels. Side effects, selection operations, and state updates are all cobbled together. This colocation can actually be kind of nice. But mix in some informal dependencies, triple the recipe, and serve it on some boilerplate and you'll see Flux break down quickly.
Other Flux implementations like Flummox and Reflux improved the boilerplate and debugging experience. While very usable, dependency management was the one nagging problem that plagued all Flux implementations. Using another store felt ugly. Deeply-nested dependency trees were hard to follow.

This ecommerce app could someday have stores for OrderHistory, ShippingCalculator, DeliveryEstimate, BananasHoarded, etc. A large app could easily have hundreds of stores. How do you keep dependencies up-to-date in every store? How do you track side effects? What about purity? What about debugging? Are bananas really a berry?
As for the programming principles introduced by Flux, unidirectional data flow was a winner, but, for now, the Law of Demeter was not.
The Singleton Model
We all know how Redux came roaring in to save the day. It ditched the concept of multiple stores in favor of a singleton model. Now everything can access everything else without any "dependencies" at all.
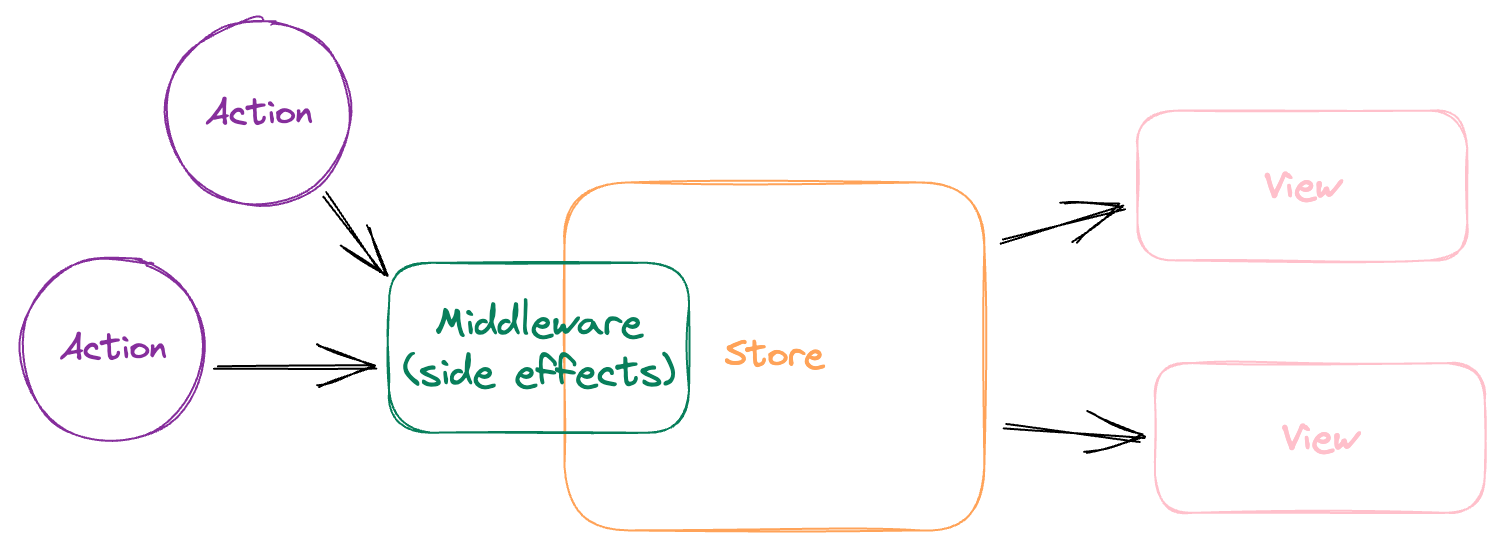
Reducers are pure, so all logic dealing with multiple state slices must go outside the store. The community made standards for managing side effects and derived state. Redux stores are beautifully debuggable. The only major Flux Flaw that Redux originally failed to fix was its boilerplate.
RTK later simplified Redux's infamous boilerplate. Then Zustand removed some fluff at the cost of some debugging power. All of these tools have become extremely popular in the React world.
With modular state, dependency trees grow so naturally complex that the best solution we could think of was, "Just don't do it I guess."

And it worked! This new singleton approach still works well enough for most apps. The Flux principles were so solid that simply removing the dependency nightmare fixed it.
Or did it?
Back to Basics
The success of the singleton approach begs the question, what was Flux getting at in the first place? Why did we ever want multiple stores?
Allow me to shed some light on this.
Reason #1: Autonomy
With multiple stores, pieces of state are broken out into their own autonomous, modular containers. These stores can be tested in isolation. They can also be shared easily between apps and packages.
Reason #2: Code Splitting
These autonomous stores can be split into separate code chunks. In a browser, they can be lazy-loaded and plugged in on the fly.
Redux's reducers are fairly easy to code-split too. Thanks to replaceReducer, the only extra step is to create the new combined reducer. However, more steps may be required when side effects and middleware are involved.
Reason #3: Standardized Primitives
With the singleton model, it's difficult to know how to integrate an external module's internal state with your own. The Redux community introduced the Ducks pattern as an attempt to solve this. And it works, at the cost of a little boilerplate.
With multiple stores, an external module can simply expose a store. For example, a form library can export a FormStore. The advantage of this is that the standard is "official", meaning people are less likely to create their own methodologies. This leads to a more robust, unified community and package ecosystem.
Reason #4: Scalability
The singleton model is surprisingly performant. Redux has proven that. However, its selection model especially has a hard upper limit. I wrote some thoughts on this in this Reselect discussion. A big, expensive selector tree can really start to drag, even when taking maximum control over caching.
On the other hand, with multiple stores, most state updates are isolated to a small portion of the state tree. They don't touch anything else in the system. This is scalable far beyond the singleton approach - in fact, with multiple stores, it's very difficult to hit CPU limitations before hitting memory limitations on the user's machine.
Reason #5: Destruction
Destroying state is not too difficult in Redux. Just like in the code-splitting example, it requires only a few extra steps to remove a part of the reducer hierarchy. But it's still simpler with multiple stores - in theory, you can simply detach the store from the dispatcher and allow it to be garbage collected.
Reason #6: Colocation
This is the big one that Redux, Zustand, and the singleton model in general do not handle well. Side effects are separated from the state they interact with. Selection logic is separated from everything. While multi-store Flux was perhaps too colocated, Redux went to the opposite extreme.
With multiple autonomous stores, these things naturally go together. Really, Flux only lacked a few standards to prevent everything from becoming a helter-skelter hodge-podge of gobbledygook (sorry).
Reasons Summary
Now, if you know the OG Flux library, you know that it actually wasn't great at all of these. The dispatcher still takes a global approach - dispatching every action to every store. The whole thing with informal/implicit dependencies also made code splitting and destruction less than perfect.
Still, Flux had a lot of cool features going for it. Plus the multiple-store approach has potential for even more features like Inversion of Control and fractal (aka local) state management.
Flux might have evolved into a truly powerful state manager if somebody hadn't named their goddess Demeter. I'm serious! ... Ok, I'm not. But now that you mention it, maybe Demeter's law deserves a closer look:
The Law of Demeter
What exactly is this so-called "law"? From Wikipedia:
Each unit should have only limited knowledge about other units: only units "closely" related to the current unit.
Each unit should only talk to its friends; don't talk to strangers.
This law was designed with Object-Oriented Programming in mind, but it can be applied in many areas, including React state management.
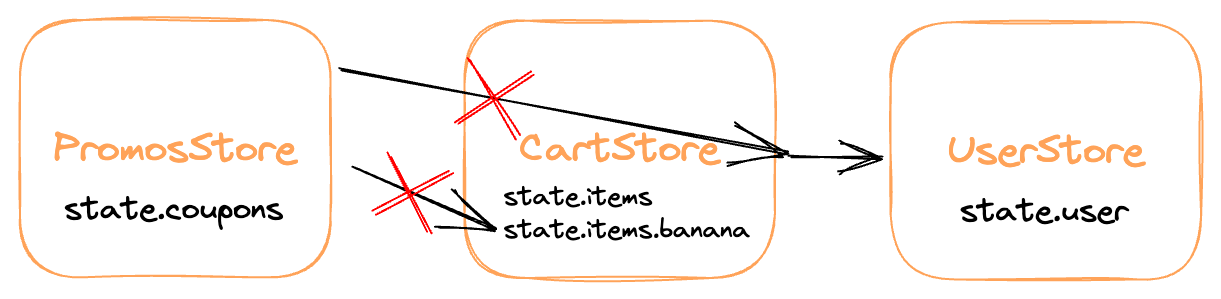
The basic idea is to prevent a store from:
- Tightly-coupling itself to another store's implementation details.
- Using stores that it doesn't need to know about.
- Using any other store without explicitly declaring a dependency on that store.
In banana terms, a banana shouldn't peel another banana and shouldn't talk to a banana in another tree. However, it can talk to the other tree if the two trees rig up a banana phone line first.
This encourages separation of concerns and helps your code stay modular, DRY, and SOLID. Solid theory! So what was Flux missing?
Well, inter-store dependencies are a natural part of a good, modular system. If a store needs to add another dependency, it should do that and do it as explicitly as possible. Here's some of that Flux code again:
PromosStore.dispatchToken = dispatcher.register(payload => {
if (payload.actionType === 'add-to-cart') {
// wait for CartStore to update first:
dispatcher.waitFor([CartStore.dispatchToken])
// now send the request
sendPromosRequest(UserStore.userId, CartStore.items).then(promos => {
dispatcher.dispatch({ actionType: 'promos-fetched', promos })
})
}
if (payload.actionType === 'promos-fetched') {
PromosStore.setPromos(payload.promos)
}
})
PromosStore has multiple dependencies declared in different ways - it waits for and reads from CartStore and it reads from UserStore. The only way to discover these dependencies is to look for stores in PromosStore's implementation.
Dev tools can't help make these dependencies more discoverable either. In other words, the dependencies are too implicit.
While this is a very simple and contrived example, it illustrates how Flux misinterpreted the Law of Demeter. While I'm sure it was mostly born of a desire to keep Flux implementations small (real dependency management is a complex task!), this is where Flux fell short.
Unlike the heroes of this story:
The Heroes
In 2020, Recoil came stumbling onto the scene. While a little clumsy at first, it taught us a new pattern that revived the multiple-store approach of Flux.
Unidirectional data flow moved from the store itself to the dependency graph. Stores were now called atoms. Atoms were properly autonomous and code-splittable. They had new powers like suspense support and hydration. And most importantly, atoms formally declare their dependencies.
The atomic model was born.
// a Recoil atom
const greetingAtom = atom({
key: 'greeting',
default: 'Hello, World!',
})
Recoil struggled with a bloated codebase, memory leaks, bad performance, slow development, and unstable features - most notably side effects. It would slowly iron out some of these, but in the meantime, other libraries took Recoil's ideas and ran with them.
Jotai burst onto the scene and quickly gained a following.
// a Jotai atom
const greetingAtom = atom('Hello, World!')
Besides being a tiny fraction of Recoil's size, Jotai offered better performance, sleeker APIs, and no memory leaks due to its WeakMap-based approach.
However, it came at the cost of some power - the WeakMap approach makes cache control difficult and sharing state between multiple windows or other realms almost impossible. And the lack of string keys, while sleek, makes debugging a nightmare. Most apps should add those back in, drastically tarnishing Jotai's sleekness.
// a (better?) Jotai atom
const greetingAtom = atom('Hello, World!')
greetingAtom.debugLabel = 'greeting'
A few honorable mentions are Reatom and Nanostores. These libraries have explored more of the theory behind the atomic model and try to push its size and speed to the limit.
The atomic model is fast and scales very well. But up until very recently, there were a few concerns that no atomic library had addressed very well:
- The learning curve. Atoms are different. How do we make these concepts approachable for React devs?
- Dev X and debugging. How do we make atoms discoverable? How do you track updates or enforce good practices?
- Incremental migration for existing codebases. How do you access external stores? How do you keep existing logic intact? How do you avoid a full rewrite?
- Plugins. How do we make the atomic model extensible? Can it handle every possible situation?
- Dependency Injection. Atoms naturally define dependencies, but can they be swapped out during testing or in different environments?
- The Law of Demeter. How do we hide implementation details and prevent scattered updates?
This is where I come in. See, I'm the principle creator of another atomic library:
Zedux
Zedux finally entered the scene a few weeks ago. Developed by a Fintech company in New York - the company I work for - Zedux was not only designed to be fast and scalable, but also to provide a sleek development and debugging experience.
// a Zedux atom
const greetingAtom = atom('greeting', 'Hello, World!')
I won't go into depth about Zedux's features here - as I said, this article won't focus on the differences between these atomic libraries.
Suffice it to say that Zedux addresses all the above concerns. For example, it's the first atomic library to offer real Inversion of Control and the first to bring us full circle back to the Law of Demeter by offering atom exports for hiding implementation details.
The last ideologies of Flux have finally been revived - not only revived but improved! - thanks to the atomic model.
So what exactly is the atomic model?
The Atomic Model
These atomic libraries have many differences - they even have different definitions of what "atomic" means. The general consensus is that atoms are small, isolated, autonomous state containers reactively updated via a Directed Acyclic Graph.
I know, I know, it sounds complex, but just wait till I explain it with bananas.
I'm kidding! It's actually really simple:
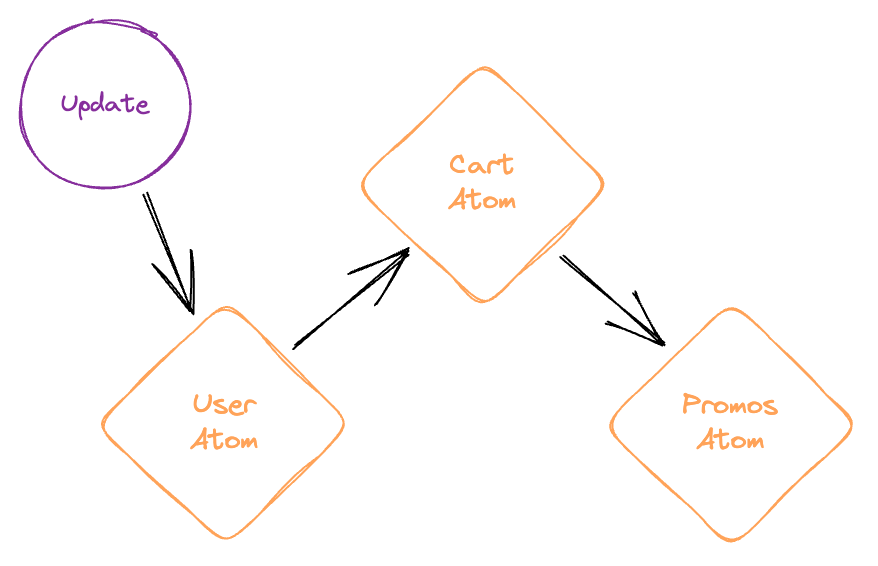
Updates ricochet through the graph. That's it!
The point is, regardless of the implementation or the semantics, all of these atomic libraries have revived the concept of multiple stores and made them not only usable, but a real joy to work with.
The 6 reasons I gave for wanting multiple stores are exactly the reasons why the atomic model is so powerful:
- Autonomy - Atoms can be tested and used completely in isolation.
- Code Splitting - Import an atom and use it! No extra considerations required.
- Standardized Primitives - Anything can expose an atom for automatic integration.
- Scalability - Updates affect only a small part of the state tree.
- Destruction - Simply stop using an atom and all its state is garbage collected.
- Colocation - Atoms naturally define their own state, side effects, and update logic.
The simple APIs and scalability alone make atomic libraries an excellent choice for every React app. More power and less boilerplate than Redux? Is this a dream?
Conclusion
What a journey! The world of React state management never ceases to amaze, and I'm so glad I hitched a ride.
We're just getting started. There is a lot of room for innovation with atoms. After spending years creating and using Zedux, I've seen how powerful the atomic model can be. In fact, its power is its Achilles heel:
When devs explore atoms, they often dig so deep into the possibilities that they come back saying, "Look at this crazy complex power," rather than, "Look at how simply and elegantly atoms solve this problem." I'm here to change this.
The atomic model and the theory behind it haven't been taught in a way that's approachable for most React devs. In a way, the React world's experience of atoms so far has been the opposite of Flux:

This article is the second in a series of learning resources I'm producing to help React devs understand how atomic libraries work and why you might want to use one. Check out the first article - Scalability: the Lost Level of React State Management.
It took 10 years, but the solid CS theory introduced by Flux is finally impacting React apps in a big way thanks to the atomic model. And it will continue to do so for years to come.